سبد خرید شما خالی است
فایل Robots.txt و تنظیم کردن آن در جنگو

 محمد رضا پودینه
محمد رضا پودینه- ۱۳ فروردین ۱۴۰۲
- 88
اگر با فرآیند سئو Seo( Search engine optimization) کمی آشنا باشید قطعا فایل Robots.txt آشنا میباشید و ممکن است برای شما برنامه نویسان جنگو سوال باشد که چگونه میتوانید این فایل را درون پروژه جنگو خود ایجاد و در اختیار ربات های گوگل بگذارید و در این فایل ما میتوانیم عملکرد ربات های خزنده وب که مهم ترین آن ها ربات های گوگل هستند را کنترل و یا حتی دسترسی آن ها به یک سری از صفحات خاص وبسایت خود را محدود کنیم
فایل Robots.txt چیست ؟
اگر بخواهیم عملکرد این فایل Robots.txt را بررسی کنیم به این صورت است به طور پیشفرض وقتی شما یک وبسایت دارید و در گوگل آن وبسایت را ثبت کرده اید ربات های گوگل برای فهمیدن محتوای شما و ایندکس کردن صفحات شما در گوگل نیاز وارد وبسایت شما میشوند و تمام صفحات وبسایت شما را مورد بررسی قرار میدهند و شاید شما نخواهید بعضی از صفحات وبسایت شما وارد نتایج گوگل شوند و از طریق فایل Robots.txt میتوانید عملکرد ربات های گوگل را کنترل و آن ها را مدیریت کنید که چه ربات هایی میتوانند از کدام صفحات شما دیدن و محتوا و لینک های آن را در گوگل به نمایش بگذارند و وبسایت شما حتما باید این فایل را داشته باشد تا ربات های گوگل منظم تر در وبسایت شما بخزند
انواع ربات های گوگل:
- ربات AdSense: این ربات برای بررسی صفحه هایی با هدف نمایش تبلیغات است
- Googlebot Image: این ربات تصاویر وبسایت شما را شناسایی و بررسی میکند
- Googlebot News: این ربات برای ایندکس کردن سایت های خبری میباشد
- Googlebot Video: این ربات برای بررسی کردن فیلم ها و ویدیوهای وبسایت شما میباشد
- Googlebot: این ربات مسئول بررسی و ایندکس کردن صفحه ی وب شما میباشد و ریسپانسیو بودن سایت شما را برای دو دستگاه Desktop و SmartPhone, بررسی میکند
نکته: توجه داشته باشید که ربات های خزنده فقط مخصوص گوگل نیستند و ربات های خزنده موتور های جست و جوی دیگر که وظیفه ی آن ها جمع آوری اطلاعات از سراسر وب را شامل میشود میباشد ولی ربات های مورد توجه ما ربات های گوگل هستند چرا که گوگل بزرگترین و بهترین موتور جست و جو میباشد و اکثر کاربر ها از گوگل استفاده میکنند پس موتور های دیگه ای مانند Bing نیز ربات های خاص خود را دارند که شما از طریق فایل Robotx.txt میتوانید تمامی ربات های فعال در سطح وب را کنترل و دسترسی های خاصی برای آنها اعمال کنید که بدانند چه صفحات و لینک هایی را میتوانند پیمایش کنند و در نتایج به کاربران خود که باعث دیده شدن وبسایت شما میشود نشان دهند
دستورات فایل Robots.txt:
همانطور که گفتیم فایل Robots.txt مخصوص ربات های خزنده وب و بخصوص ربات های گوگل میباشد و آن ربات ها برای درک اجازه دسترسی به یک صفحه یا یک لینک یک سری دستورات دارند که برای آنها قابل درک است حال به بررسی دستورات فایل Robots.txt میپردازیم.

لیست دستورات فایل Robots.txt:
- User-agent: با استفاده از این دستور میتوانید مشخص کنید که هدف شما کنترل کدام نوع از ربات های خزنده سطح وب میباشد
- Disallow: این دستور ربات خزنده را محدود میکند و به آن اجازه دسترسی به آن صفحه را نمیدهد و خزنده نمیتواند در آن صفحه به اصطلاح بخزد و لینک های آن را استخراج کند
- Allow: هر صفحه و لینکی که در مقابل این دستور قرار بگیرد به این معناست که ربات میتواند از آن صفحه بازدید کند و لینک های آن را استخراج کند
- Sitemap: این دستور نقشه سایت شما را به ربات خزنده میدهد تا با نقشه وبسایت شما آشنا بشود و به راحتی بتواند در آن بخزد
برای آشنایی با لیست ربات های خزنده ی وب میتوانید وارد وبسایت Robots.org شوید و همچنین دستورات فایل های Robots.txt را نیز در آنجا مشاهده کنید
نحوه ی ایجاد کردن فایل Robots.txt:
بعد از آشنا شدن با فایل Robots.txt و دستورات آن حال نیاز است که این فایل را ایجاد کرده و با نحوه ی کاربرد بیشتر این دستورات آشنا شویم برای درک بهتر دستورات به تصویر زیر دقت کنید یک فایل txt با اسم Robots ایجاد کنید
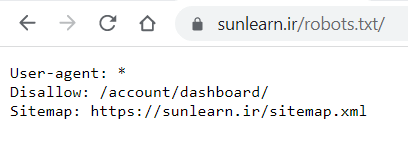
در ابتدای این فایل با استفاده از دستور User-agent مشخص میکنیم که میخواهیم برای کدام ربات ها قابلیت های دسترسی و عدم دسترسی را قرار دهیم دقت داشته باشید که اگر * را قرار بدهید یعنی تمامی ربات های سطح وب ربات های مورد انتخاب شما میباشند
*:User-agent
یا میتوانید با نوشتن نام آن ربات مورد نظر فقط دسترسی یا عدم دسترسی را برای آن ربات مشخص کنید به این صورت برای مثال ما ربات گوگل را انتخاب کردیم
User-agent:Google
چگونگی محدود کردن صفحات از ربات های خزنده:
طبق دستوراتی که بررسی کردیم میتوانیم با نوشتن آدرس یک صفحه مقابل دستور Disallow دسترسی به آن صفحه را برای ربات ها محدود کنیم برای مثال ما در سان لرن صفحه داشبورد کاربر ها را برای ربات های خزنده محدود کرده ایم دقت داشته باشید که اگر میخواهید صفحه ای را محدود کنید
نیازی نیست که آدرس دامنه خود را نیز قبل از آدرس آن صفحه قرار دهید آدرس شما باید به این صورت باشد مثلا ما میخواهیم صفحه تماس باما یک وبسایت را Disallow کنیم کد ما باید به این صورت باشد
/Disallow: /contact-us
حال با استفاده از کد هایی که برای مدیریت ربات ها یاد گرفته ایم میتوانیم آن دستورات را در صورت نیاز با هم ادغام کنیم
User-agent:Google
:Disallow
*:User-agent
/:Disallow
دستوراتی که نوشتیم به این صورت است که ربات گوگل میتواند وارد وبسایت ما شود و در تمام صفحات بخزد ولی سایر ربات ها نمیتوانند وارد وبسایت ما شوند وقتی Disallow را خالی گداشتیم یعنی اینکه این ربات هیچ محدودیتی ندارد ولی وقتی در قسمت ربات های دیگر / را قرار دادیم یعنی سایر ربات ها دسترسی به هیچ صفحه ای از وبسایت ما ندارند, میتوانستیم برای ربات گوگل به جای اینکه Disallow قرار دادیم یک allow بگذاریم به این صورت:
User-agent:Google
/:Allow
*:User-agent
/:Disallow
قرار دادن فایل Robots.txt برای پروژه جنگو:
بعد از ایجاد کردن فایل Robots.txt و نوشتن دستورات آن نیاز است که این فایل را به وبسایت خود اضافه کنید دقت داشته باشید که این فایل باید در Root اصلی وبسایت شما باشد یعنی اینکه اگر دامنه شما example.com میباشد باید فایل Robots.txt شما در آدرس example.com/robots.txt باشد و این یک آدرس Url معتبر برای قرارگیری این فایل میباشد
1-در مرحله اول ابتدا فایل Robots.txt که ساختید را درون فولدر templates پروژه خود کپی کرده
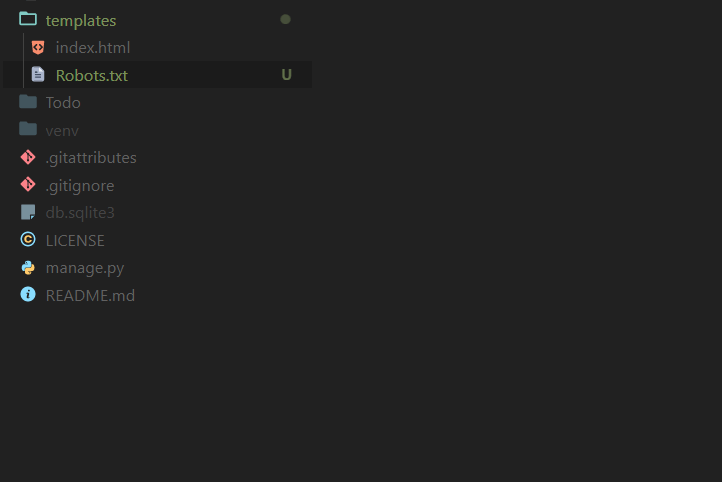
2-حال نیاز است تا View مورد نظر برای پردازش فایل Robots.txt در جنگو را ایجاد کنیم که فایل را پردازش و در خروجی به کاربر به عنوان txt نمایش دهد
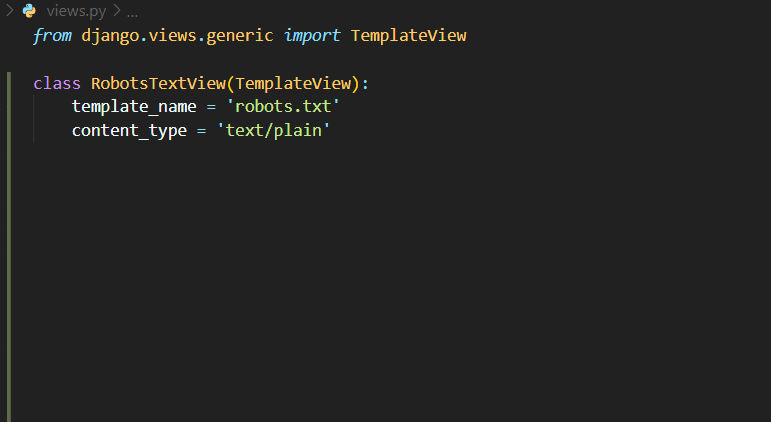
در view مورد نظر در ابتدا TemplateView را ایمپورت کرده و به عنوان template_name آدرس فایل robots.txt را که درون فولدر templates ذخیره کردیم را میدهیم چون فایل ما درون روت اصلی فولدر templates قرار دارد فقط اسم فایل مورد نظر را به آن میدهیم
content_type: مشخص میکند که خروجی که این view باید برگرداند به چه صورت باید باشد و چون ما به خروجی text برای فایل Robots.txt نیاز داریم
برابر با text/plain قرار میدهیم
3- حال نیاز است تا view که برای پردازش فایل خود آماده کردیم را به یک url متصل کنیم دقت کنید باید آدرس url شما برابر با robots.txt باشد
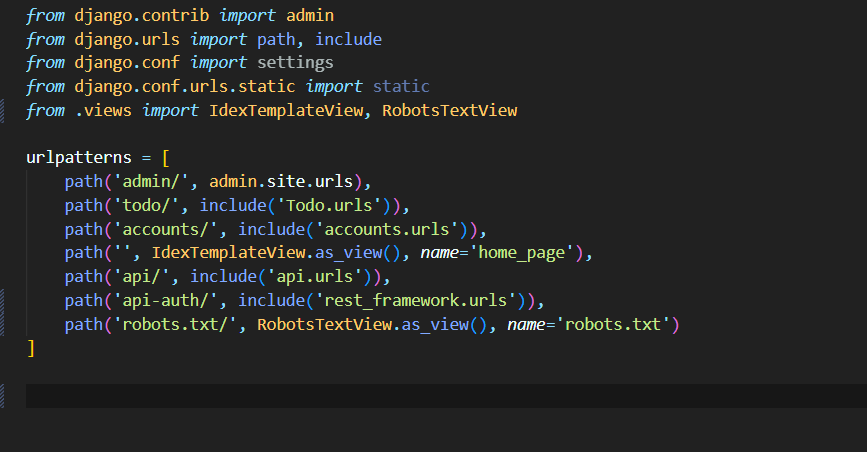
4- تبریک حال میتوانید خروجی آدرس robots.txt را مشاهده کنید دقت داشته باشید که حتما باید نام url شما robots.txt باشد ! حال برای تست پس از اجرای پروژه به آدرس 127.0.0.1:8000 میرویم
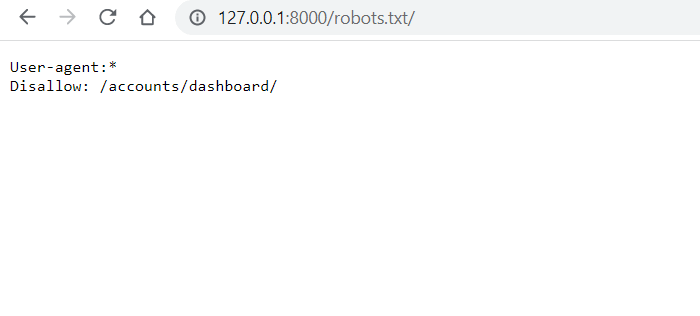
جمع بندی: فایل Robots.txt یک فایل خیلی مهم با لیستی از دستورات خاص برای وبسایت شما میباشد زیرا که این فایل وظیفه ی کنترل دسترسی ربات های خزنده سطح وب را دارد و موتور های جست و جو میتوانند از طریق این فایل متوجه بشوند که چه صفحاتی را نباید بررسی قرار دهند و دارا بودن فایل Robots.txt برای شما که بخواهید وبسایت خود را برای گوگل نیز بهینه کنید ضروری است وتوانستیم در انتها این فایل را در جنگو نیز پردازش کنیم زیرا ممکن است کارفرمای شما به شما گفته باشد که این فایل را نیز باید در پروژه قرار دهید
نظر خود را اینجا بگذارید
برای درح نظر ابتدا وارد شوید !
نظرات